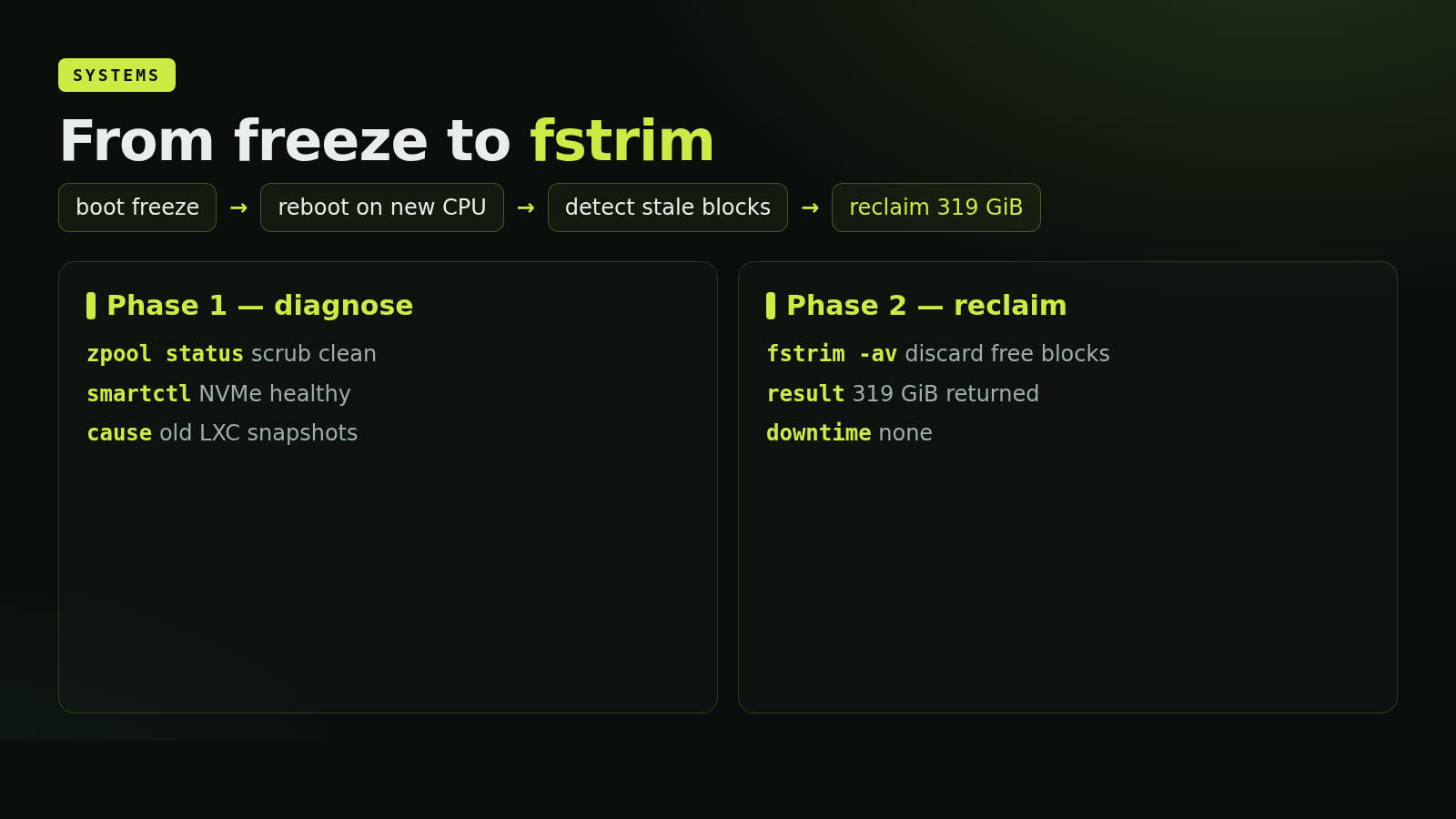
clusterFer son dos hosts Proxmox, pve1 y host1, compartiendo un mismo /etc/pve vía corosync. host1 llevaba semanas en silencio. Lo reconstruí sobre una CPU distinta, peleé contra un boot congelado, lo devolví al quórum, y entonces me di cuenta de que su NVMe de 500 GB tenía 319 GiB de bloques libres que el SSD no conocía.
Esta es la historia de cómo clusterFer recuperó su segundo nodo, y lo que encontré una vez pude entrar.
La migración de hardware
El chasis viejo de host1 era un 8 x AMD FX(tm)-8350 Eight-Core Processor (1 Socket) con 16 GB de RAM y tres discos: un SATA de 4 TB para el sistema y un pool LVM-thin legacy, un NVMe de 500 GB (Crucial P1, QLC) para los CTs y VMs activos, y un segundo SATA de 4 TB para backups exportados vía NFS. Proxmox 8.x se instaló hace años y nunca se reinstaló. La placa murió.
Moví los discos a un chasis distinto con un Xeon E5-2680 v4 y 32 GB de RAM, esperando que Proxmox arrancara sobre la CPU nueva y se apañara. GRUB salió, elegí Proxmox Boot, y se quedó en:
Loading Linux 6.8.12-4-pve ... Loading initial ramdisk ...
Y se acabó. Sin kernel panic, sin más output, sin reacción a las teclas. O el sistema seguía cargando en silencio, o el initramfs se estaba peleando con el hardware nuevo - la placa AMD tenía otro chipset entero, y los controladores SATA también eran distintos. Lo dejé estar, power-cycle, otra intentona. Después de varios intentos el kernel arrancó, el sistema se levantó, y pude entrar por SSH. El stack de boot sobrevivió al cambio de CPU; lo que paralizó los primeros intentos parece a posteriori un handshake lento de firmware que GRUB no reportaba visualmente.
De vuelta en el quórum
Desde pve1 comprobé corosync:
$ pvecm status
Cluster information
-------------------
Name: clusterFer
Nodes: 2
Quorate: Yes
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 192.168.1.200
0x00000002 1 192.168.1.2 (local)
Los dos nodos online, en quórum. /etc/pve ya estaba sincronizado. host1 tenía 47 contenedores LXC y 18 VMs en inventario, solo un CT corriendo. Empecé a mirar el almacenamiento para confirmar que todo lo que me importaba seguía ahí.
El árbol de snapshots LVM-thin, la razón por la que host1 existe
host1 siempre ha sido el nodo experimental. La razón es su layout de almacenamiento NVMe: un único pool LVM-thin, nvme/data, con 47 volúmenes thin formateados ext4 dentro. Cada disco de CT y VM vive en ese pool, y los snapshots son LVs thin independientes que comparten bloques vía copy-on-write con granularidad de 256 KiB.
Lo que hace eso interesante en Proxmox es el campo parent: en /etc/pve/lxc/<id>.conf. No solo registra una historia lineal; registra un árbol. CT 244 es el ejemplo canónico. Su árbol de snapshots:
rootAccess
+- Odoo16_oca_manual
+- Odoo16_oca_working (current head)
+- Odoo17_oca
| +- Odoo17_workiing
+- Odoo14_not_working
+- Odoo_18_working
+- Documents
+- visualCodeConfigSettings
Desde la misma base había ramificado cinco instalaciones distintas de Odoo (14, 16 manual, 16 OCA, 17, 18) y una rama de herramientas de escritura. Hacer rollback a una no borra las demás. ZFS soporta la misma forma vía zfs clone, pero la UI de Proxmox para LXC sobre ZFS no lo expone igual; trata los snapshots como una línea. El NVMe de host1 se había convertido en mi entorno "prueba cosas y vuelve sin perder las otras ramas" durante cuatro años.
Eso ahora importaba porque necesitaba confirmar que el árbol seguía intacto. Lo estaba. pct listsnapshot 244 seguía listando los nueve snapshots; lo mismo para CT 1002 con sus siete. El cambio de hardware no había tocado los metadatos LVM.
El problema del 11% de desgaste
Ya que estaba dentro, lancé SMART contra el NVMe:
Model Number: CT500P1SSD8 Percentage Used: 11% Data Units Written: 42,702,673 [21.8 TB] Available Spare: 100%
Un 11% de desgaste tras 21,8 TB escritos es sano para QLC, pero me planteó una pregunta que nunca había hecho: ¿estaba el SSD recibiendo TRIM realmente? Lo comprobé.
systemctl is-enabled fstrim.timeren el host:disabled. Nunca se ejecutó./etc/lvm/lvm.conf:thin_pool_autoextend_threshold = 100. Autoextend desactivado, sin aviso temprano.lvs --segments -o +zero,discards nvme/data:zero passdown.passdownestá bien, perozeroactivo significa que el pool zerea cada chunk reusado - duplicando escrituras gratis.- 43 de los 47 contenedores LXC son unprivileged.
fstrimdesde dentro falla conFITRIM ioctl: Operation not permitted. Elfstrim.timerupstream de systemd se autodesactiva conConditionVirtualization=!container. - Las VMs no tenían
discard=onen las líneas de disco. El TRIM del guest no tenía camino a través de QEMU.
El controlador QLC llevaba cuatro años haciendo garbage collection sin saber nunca qué bloques estaban libres de verdad. Tocaba arreglarlo.
Fase 1: sin downtime
En pve1 (ZFS rpool, NVMe Predator de 4 TB, 2% de desgaste):
zpool set autotrim=on rpool zpool trim rpool zfs set atime=off rpool zfs set xattr=sa rpool systemctl enable --now zfs-scrub-monthly@rpool.timer
En host1 (LVM-thin nvme/data, NVMe QLC, 11% de desgaste):
lvchange --zero n nvme/data systemctl enable --now fstrim.timer sed -i 's/thin_pool_autoextend_threshold = 100/thin_pool_autoextend_threshold = 80/' /etc/lvm/lvm.conf # install /usr/local/bin/check-thinpool.sh + /etc/cron.d/check-thinpool
Y a nivel de cluster, como /etc/pve es compartido, restringí cada storage al host que es su dueño:
pvesm set local-lvm --nodes host1 pvesm set nvme-lvm --nodes host1 pvesm set zfs-storage --nodes pve1
Hasta entonces ambos nodos se mostraban los storages del otro como inactive en la UI - no roto, simplemente sucio.
Fase 2: en caliente
Para las VMs añadí discard=on,ssd=1 a cada disco en storage LVM-thin. Un script Python pequeño, add_discard.py, parseaba cada .conf, editaba solo la sección activa (todo antes del primer header [snapshot_name]), y saltaba líneas cuyo storage no fuera LVM-thin.
Para LXC la historia fue menos limpia. El schema de Proxmox 8 rechaza discard=on en rootfs: para LXC; esa opción no existe para contenedores. Y como ya había visto, los contenedores unprivileged no pueden hacer FITRIM. La única forma de que el TRIM llegue al SSD para volúmenes LXC es offline:
- Para el contenedor.
- Monta su volumen thin en el host con
mount -o discard /dev/nvme/vm-XXX-disk-0 /mnt/trim-XXX. - Lanza
fstrim -v /mnt/trim-XXX. - Desmonta, arranca el contenedor de nuevo.
Lo escribí como /usr/local/bin/trim-lxc.sh y lo lancé contra todos los CTs en nvme-lvm. Los números, en bytes que por fin volvieron al SSD:
CT 188: 23.3 GiB CT 245: 18.1 GiB CT 515: 32.2 GiB
CT 227: 4.6 GiB CT 246: 20.3 GiB CT 516: 26.6 GiB
CT 234: 15.3 GiB CT 513: 16.6 GiB CT 519: 20.8 GiB
CT 236: 27.4 GiB CT 514: 2.1 GiB CT 1000: 18.0 GiB
CT 237: 16.6 GiB CT 244: 16.6 GiB CT 1001: 18.8 GiB
CT 1002: 9.9 GiB CT 1003: 18.9 GiB CT 1004: 13.8 GiB
~319 GiB total
El thin pool en sí mismo bajó del 60,35% al 54,82%. La mayor parte de los 319 GiB nunca se liberó a nivel de pool porque seguían referenciados por algún snapshot del DAG; pero el SSD ahora sabe que eran bytes no asignados desde la perspectiva del pool. Desde la vista del controlador, se han borrado 319 GiB de referencias rancias.
El pool local-lvm que no era
Un detalle me seguía picando. pvesm status en host1 reportaba local-lvm como inactive con este mensaje:
activating LV 'pve/data' failed: Activation of logical volume pve/data is prohibited while logical volume pve/data_tmeta is active.
Bug clásico de activación parcial de LVM-thin. udev había levantado el LV de metadatos directamente, dejando al thin pool padre incapaz de engancharlo. El fix son tres llamadas a lvchange, archivadas en un script minúsculo:
$ cat /root/fixLVpveData.sh lvchange -an pve/data_tdata lvchange -an pve/data_tmeta lvchange -ay pve/data
Lo lancé. pve/data subió con atributo twi-aotz-- (active, open, thin pool, zero), los sub-LVs se reengancharon limpiamente, y local-lvm en pvesm status pasó de inactive a active 48.65%. 3,49 TiB de volúmenes thin legacy de vuelta en juego.
La trampa del schema
Ahí fue cuando pillé mi propio bug. Con local-lvm activo, Proxmox revalidó todos los configs de VM que dependían de él. Cinco VMs no parseaban:
vm 405 - unable to parse value of 'virtio0' - format error ssd: property is not defined in schema and the schema does not allow additional properties
Mi script de la Fase 2 había añadido a manta ,discard=on,ssd=1 a cada disco. Resulta que ssd=1 no está en el schema de las líneas virtio* - solo en las scsi* y sata*. virtio-blk no expone rotational rate, así que QEMU no tiene un concepto de emulación SSD para él; la opción se rechaza, y Proxmox 8 valida estrictamente en lugar de aceptarla en silencio como hacían versiones más viejas.
Un script de seguimiento minúsculo quitó ,ssd=1 de las líneas virtio* y dejó discard=on en su sitio. Cinco VMs (101, 306, 405, 408, 409) volvieron a parsear. Ninguna estaba arrancada, así que no hubo impacto operativo - pero si no hubiera visto los warnings me habría tropezado con esto la próxima vez que alguien intentara arrancar una.
Estado final
Name Status Used Total % local-lvm lvmthin active 1.7 TiB 3.5 TiB 48.65 nvme-lvm lvmthin active 249 GiB 465 GiB 54.82 backupHost1 nfs active 2.5 TiB 3.6 TiB 68.44
Los dos nodos en quórum, cada storage limitado a su dueño, autotrim activo en el pool ZFS root, fstrim semanal en host1, zero-on-reuse desactivado en el pool QLC, autoextend al 80% con alerta cron en /usr/local/bin/check-thinpool.sh, VMs listas para mandar TRIM al SSD en su próximo arranque, y 319 GiB de bloques libres rancios por fin devueltos al controlador.
Las lecciones
Migrar Proxmox de hardware suele funcionar sin más. El boot congelado que me asustó en el primer intento se resolvió solo en un reboot posterior. El initramfs modular de Proxmox y el kernel moderno aceptaron sin protestar una CPU distinta, otro chipset y otros controladores SATA. Debí haberle dado más tiempo al primer arranque antes de asumir que se había colgado.
El DAG de snapshots de LVM-thin es de verdad mejor que ZFS para el flujo "prueba una rama y vuelve" en LXC sobre Proxmox. Cinco versiones de Odoo ramificadas desde una misma base, cuatro años después, todas todavía revertibles, sin conflictos de merge. La UI de Proxmox expone ese árbol directamente vía el campo parent:. ZFS podría hacer lo mismo con clones, pero la UI no te deja.
LXC unprivileged más LVM-thin igual a cero TRIM salvo que montes un workaround. El contenedor no puede hacer FITRIM, el fstrim del host no ve los mounts del contenedor, y la opción discard=on por disco no existe para rootfs en el schema. Para, monta en el host, fstrim, arranca. Si tienes cientos de miles de borrados de ficheros en tus CTs, le debes esto a tu SSD.
La validación del schema es por tipo de disco. ssd=1 en virtio* rompe el parseo en Proxmox 8. Lee el schema, o usa la UI para añadir opciones de disco y copia lo que produce.
9 de mayo de 2026 - escrito desde pve1, los dos nodos en quórum, host1 ronroneando sobre un Xeon al que no conocía antes de esa mañana.