Durante mucho tiempo goberné mis servidores a ciegas. Dos nodos Proxmox en casa, una máquina de backup, dos equipos en OVH y un servidor de correo, y ningún sitio único que me avisara de que alguno estaba en apuros.
El día que un corte de luz tumbó la casa, me di cuenta de que no tenía ni idea de cuánto aguantarían las baterías ni qué máquinas habían sobrevivido. Así que me construí una sala de control, y se llama argos.
Un contenedor para vigilarlos a todos
argos es un pequeño contenedor Debian en mi primer nodo Proxmox, con dos piezas: una base de datos de series temporales InfluxDB que guarda los números, y Grafana que los dibuja. Todo lo que me importa reporta ahí.
Proxmox ya sabe enviar sus propias métricas, así que los dos nodos de casa y el de OVH alimentan InfluxDB directamente. El servidor de backup envía sus estadísticas por su propia API de métricas. Y sobre el metal desnudo añadí Telegraf, que cubre los huecos que las métricas nativas no ven: temperatura del procesador y de la tarjeta gráfica, y tiempo de actividad. Los dos equipos que viven en OVH llegan a casa por un túnel SSH blindado que solo puede reenviar a la base de datos y nada más.
Saber en el momento en que se va la luz
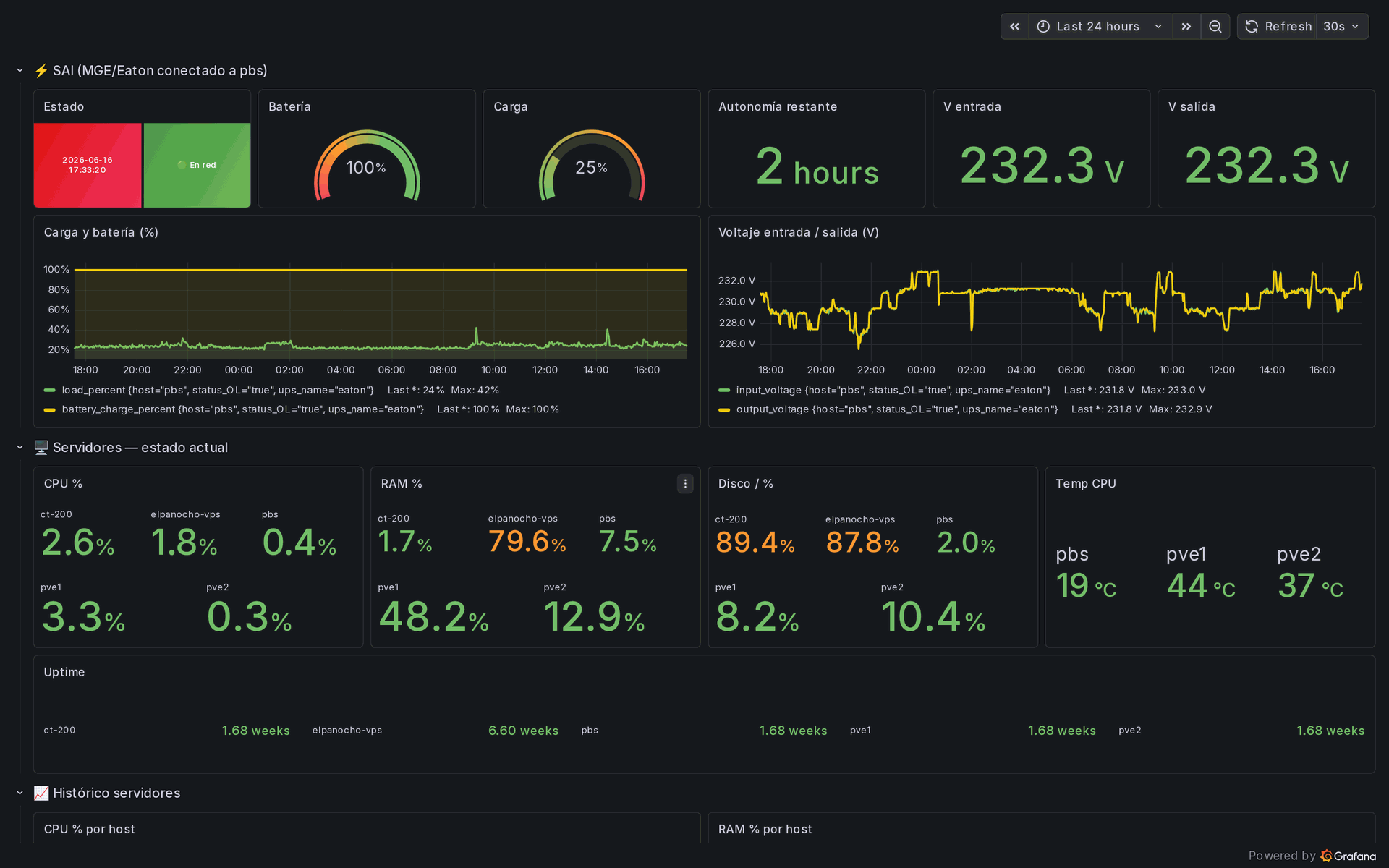
La pieza que más echaba en falta era el SAI. Hay una unidad MGE Eaton conectada por USB al servidor de backup y gestionada por NUT. Telegraf la lee y envía los números que importan: carga de la batería, consumo, autonomía estimada, y el voltaje de entrada y de salida.
Ahora, en cuanto cae la red eléctrica, el servidor de backup grita por Telegram a través del mismo bot que ya usa mi asistente de voz Maria, y el panel me muestra exactamente cuántos minutos de batería me quedan.
Una sola pantalla, toda la infraestructura
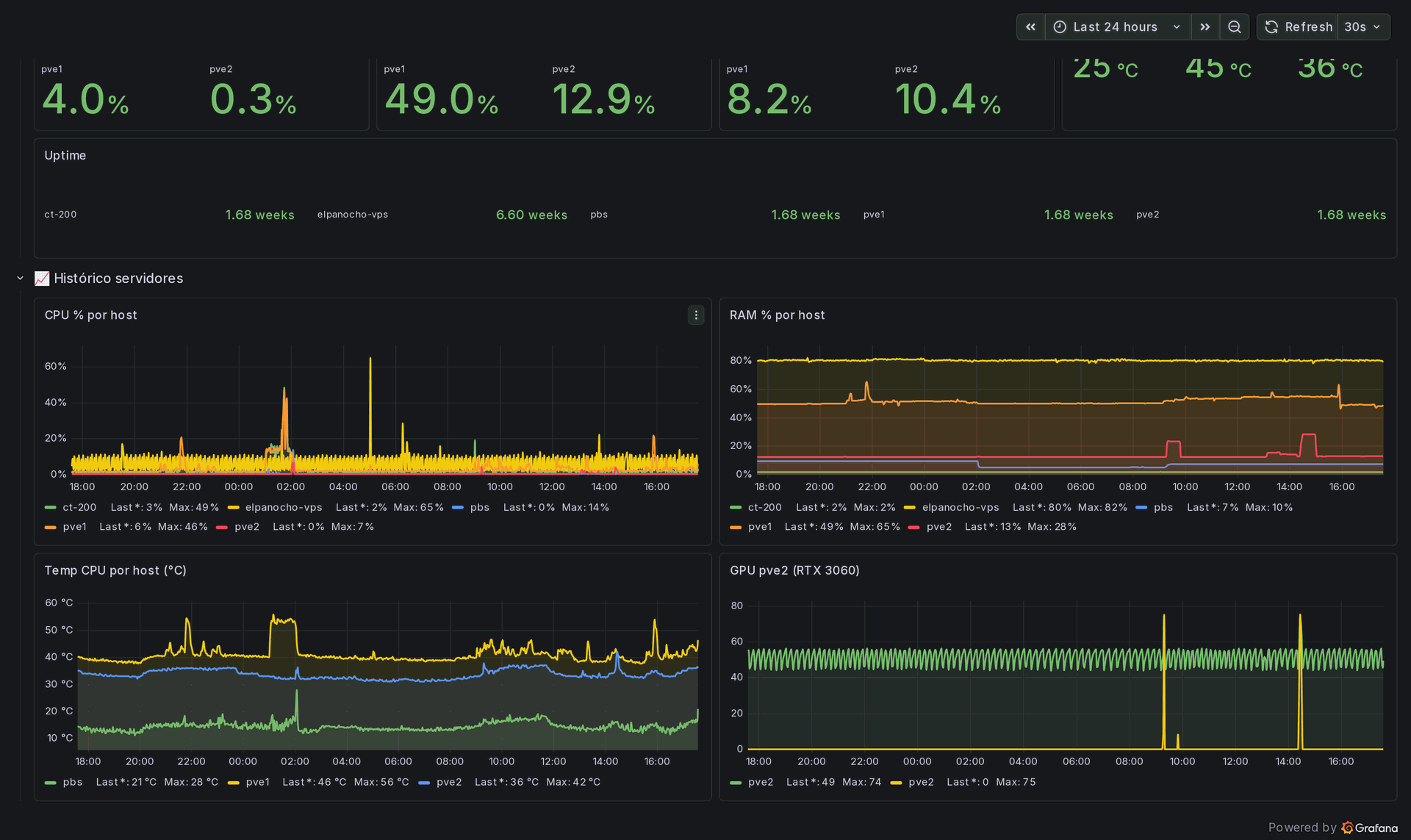
El resultado es un único panel llamado Infra LTC, el SAI y los servidores. La fila superior es el SAI: estado, batería al cien por cien, consumo en torno a un cuarto, dos horas de autonomía y unos estables doscientos treinta voltios de entrada y de salida. Debajo, cada servidor con su procesador, memoria, disco, temperatura y tiempo de actividad, coloreados en verde, ámbar o rojo según umbrales sensatos.
Debajo hay un día entero de histórico de cada equipo, más la temperatura de la tarjeta gráfica que uso para mis experimentos de IA local. Cinco reglas de alerta vigilan las cosas aburridas pero peligrosas, un disco por encima del ochenta y cinco por ciento o la memoria por encima del noventa, y avisan a mi móvil antes de que lleguen a ser una caída.
Escrito, no improvisado
Nada de esto vive solo en mi cabeza. Todo el montaje, la telemetría, las alertas y el generador del panel, está en un repositorio git con los secretos fuera, así que puedo reconstruir la sala de control desde cero en una máquina nueva en minutos.
El objetivo nunca fueron las gráficas bonitas. Era convertir un montón de servidores que fallaban en silencio en una infraestructura que me dice, en voz alta, en el momento en que algo va mal.